Dall’idea alla realizzazione: crea una funzione AI personalizzata per la descrizione delle immagini
Con il nostro agente AI puoi andare oltre le azioni standard dell’editor e aggiungere funzioni personalizzate su misura per le tue esigenze. Questo articolo illustra la creazione della funzione describeImage e spiega come trasforma le immagini in titoli, didascalie e testi alt accessibili.

L’idea
L’obiettivo è semplice. Selezionare un’immagine, fornire una breve istruzione e ricevere un testo generato inserito esattamente dove serve. La funzione supporta casi d’uso comuni come titoli di immagini, didascalie e testo alternativo, evitando supposizioni sulle intenzioni dell’utente grazie all’uso di prompt espliciti.
Progettare la funzione
Per rendere la funzione disponibile al motore AI di ONLYOFFICE, è stata definita come RegisteredFunction. Questa definizione specifica il nome della funzione, i parametri attesi e prompt di esempio che dimostrano l’uso previsto.
let func = new RegisteredFunction({
name: "describeImage",
description:
"Allows users to select an image and generate a meaningful title, description, caption, or alt text for it using AI.",
parameters: {
type: "object",
properties: {
prompt: {
type: "string",
description:
"instruction for the AI (e.g., 'Add a short title for this chart.')",
},
},
required: ["prompt"],
},
examples: [
{
prompt: "Add a short title for this chart.",
arguments: { prompt: "Add a short title for this chart." },
},
{
prompt: "Write me a 1-2 sentence description of this photo.",
arguments: {
prompt: "Write me a 1-2 sentence description of this photo.",
},
},
{
prompt: "Generate a descriptive caption for this organizational chart.",
arguments: {
prompt:
"Generate a descriptive caption for this organizational chart.",
},
},
{
prompt: "Provide accessibility-friendly alt text for this infographic.",
arguments: {
prompt:
"Provide accessibility-friendly alt text for this infographic.",
},
},
],
});
Questa definizione ha due scopi:
- Informare il motore AI di ONLYOFFICE sulle capacità della funzione e sugli input attesi.
- Fornire esempi di utilizzo per guidare sia l’AI sia gli utenti finali.
Implementare la logica
Il metodo call contiene la funzionalità effettiva eseguita quando l’utente richiama la funzione:
- Recuperare l’immagine selezionata – usando GetImageDataFromSelection, recuperiamo l’immagine dal documento. Filtriamo anche le immagini segnaposto per garantire risultati AI significativi.
- Costruire il prompt AI – l’istruzione dell’utente viene combinata con il contesto dell’immagine selezionata per creare un prompt chiaro e utilizzabile.
- Verificare la compatibilità del modello AI – solo i modelli con supporto visivo (come GPT-4V o Gemini) possono elaborare immagini. Avvisiamo l’utente se il modello attuale non può gestire immagini.
- Inviare la richiesta all’AI – l’immagine e il prompt vengono inviati al motore AI tramite chatRequest, raccogliendo il testo generato in tempo reale.
- Inserire il testo generato dall’AI nel documento – la funzione rileva se un’immagine è selezionata o meno e inserisce il risultato nel punto corretto.
- Gestione degli errori – la funzione gestisce in modo elegante immagini mancanti, modelli non supportati o errori AI imprevisti, fornendo messaggi chiari all’utente.
1. Recuperare l’immagine selezionata
In ONLYOFFICE, le immagini in un documento sono chiamate disegni. Per elaborare un’immagine selezionata dall’utente, utilizziamo l’API dei plugin di ONLYOFFICE:
let imageData = await new Promise((resolve) => {
window.Asc.plugin.executeMethod(
"GetImageDataFromSelection",
[],
function (result) {
resolve(result);
}
);
});
- GetImageDataFromSelection è un metodo dei plugin ONLYOFFICE che estrae l’immagine attualmente selezionata come stringa codificata in base64.
- Il risultato è un oggetto, di solito:
{
"src": "data:image/png;base64,iVBORw0K...",
"width": 600,
"height": 400
}
Questa stringa src contiene l’intera immagine in formato Base64, che può essere inviata direttamente ai modelli AI che accettano dati immagine.
Considerazioni chiave:
- Se non è selezionata alcuna immagine, imageData è null.
- Alcuni utenti potrebbero selezionare grafica segnaposto o rettangoli vuoti. Ad esempio, ONLYOFFICE utilizza un piccolo rettangolo bianco come segnaposto per immagini vuote. Lo confrontiamo con la sua rappresentazione base64 per filtrarli:
const whiteRectangleBase64 = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mP8/5+hHgAHggJ/PchI7wAAAABJRU5ErkJggg==";
if (imageData.src === whiteRectangleBase64) {
console.log("describeImage: Image is white placeholder");
await insertMessage("Please select a valid image first.");
return;
}
2. Preparare l’immagine per l’AI
I modelli AI si aspettano immagini come URL o dati codificati in base64, in genere in un campo come image_url. Nella nostra funzione, passiamo l’immagine insieme a un prompt testuale in un array strutturato:
let messages = [
{
role: "user",
content: [
{ type: "text", text: argPrompt },
{
type: "image_url",
image_url: { url: imageData.src, detail: "high" },
},
],
},
];
- type: “text” fornisce le istruzioni del prompt (ad esempio, “Aggiungi una didascalia descrittiva”).
- type: “image_url” include l’immagine stessa. Il motore AI può quindi analizzarla e generare testo pertinente.
- detail: “high” è un suggerimento opzionale per elaborare l’immagine alla massima risoluzione.
Logica di trasformazione:
- ONLYOFFICE fornisce src come stringa base64.
- I modelli AI possono accettare dati base64 o un URL accessibile. Qui usiamo direttamente il base64 per evitare il caricamento su un server esterno.
- Racchiudiamo l’immagine in un oggetto compatibile con l’API di richiesta chat dell’AI. Questa struttura consente più tipi di contenuto in un singolo messaggio.
3. Invio della richiesta all’AI
Una volta strutturati immagine e prompt, utilizziamo il motore del plugin AI di ONLYOFFICE:
let requestEngine = AI.Request.create(AI.ActionType.Chat);
await requestEngine.chatRequest(messages, false, async function (data) {
console.log("describeImage: chatRequest callback data chunk", data);
if (data) {
resultText += data;
}
});
- AI.ActionType.Chat consente di inviare messaggi in stile chat, in cui prompt e immagine vengono analizzati insieme.
- Il callback raccoglie porzioni di testo della risposta AI in tempo reale.
- Prima dell’invio, verifichiamo se il modello AI selezionato supporta la visione. Solo alcuni modelli (GPT-4V, Gemini) possono gestire immagini:
const allowVision = /(vision|gemini|gpt-4o|gpt-4v|gpt-4-vision)/i;
if (!allowVision.test(requestEngine.modelUI.name)) {
console.warn("describeImage: Model does not support vision", requestEngine.modelUI.name);
await insertMessage(
"⚠ This model may not support images. Please choose a vision-capable model (e.g. GPT-4V, Gemini, etc.)."
);
return;
}
4. Inserire l’output AI nel documento
Dopo aver ricevuto l’output dell’AI, il testo deve essere inserito nel documento ONLYOFFICE. La logica gestisce due casi:
- Immagine selezionata: inserire un paragrafo dopo l’immagine.
- Nessuna immagine selezionata: inserire un paragrafo dopo la posizione corrente del cursore.
async function insertMessage(message) {
console.log("describeImage: insertMessage called", message);
Asc.scope._message = String(message || "");
await Asc.Editor.callCommand(function () {
const msg = Asc.scope._message || "";
const doc = Api.GetDocument();
const selected =
(doc.GetSelectedDrawings && doc.GetSelectedDrawings()) || [];
if (selected.length > 0) {
for (let i = 0; i < selected.length; i++) {
const drawing = selected[i];
const para = Api.CreateParagraph();
para.AddText(msg);
drawing.InsertParagraph(para, "after", true);
}
} else {
const para = Api.CreateParagraph();
para.AddText(msg);
let range = doc.GetCurrentParagraph();
range.InsertParagraph(para, "after", true);
}
Asc.scope._message = "";
}, true);
- Api.GetSelectedDrawings() recupera le immagini (disegni) attualmente selezionate.
- Api.CreateParagraph() crea un nuovo oggetto paragrafo.
- InsertParagraph(para, “after”, true) inserisce il testo generato immediatamente dopo l’immagine o il paragrafo selezionato.
- Questo garantisce un’integrazione fluida: l’output AI appare sempre nel contesto giusto.
5. Gestione dei casi limite e degli errori
Alcune sfide hanno richiesto particolare attenzione:
- Nessuna immagine selezionata – chiedere all’utente di selezionarne una.
- Modello AI non supportato – avvisare l’utente prima di inviare la richiesta.
- Risposta AI vuota – informare l’utente che l’AI non è riuscita a generare una descrizione.
- Errori imprevisti – utilizzare try/catch annidati per terminare in sicurezza eventuali azioni dell’editor in corso:
} catch (e) {
try {
await Asc.Editor.callMethod("EndAction", ["GroupActions"]);
await Asc.Editor.callMethod("EndAction", [
"Block",
"AI (describeImage)",
]);
} catch (ee) {
```
}
```
Questo garantisce che il documento rimanga stabile anche se l’AI o il plugin falliscono durante l’operazione.
Risultato finale
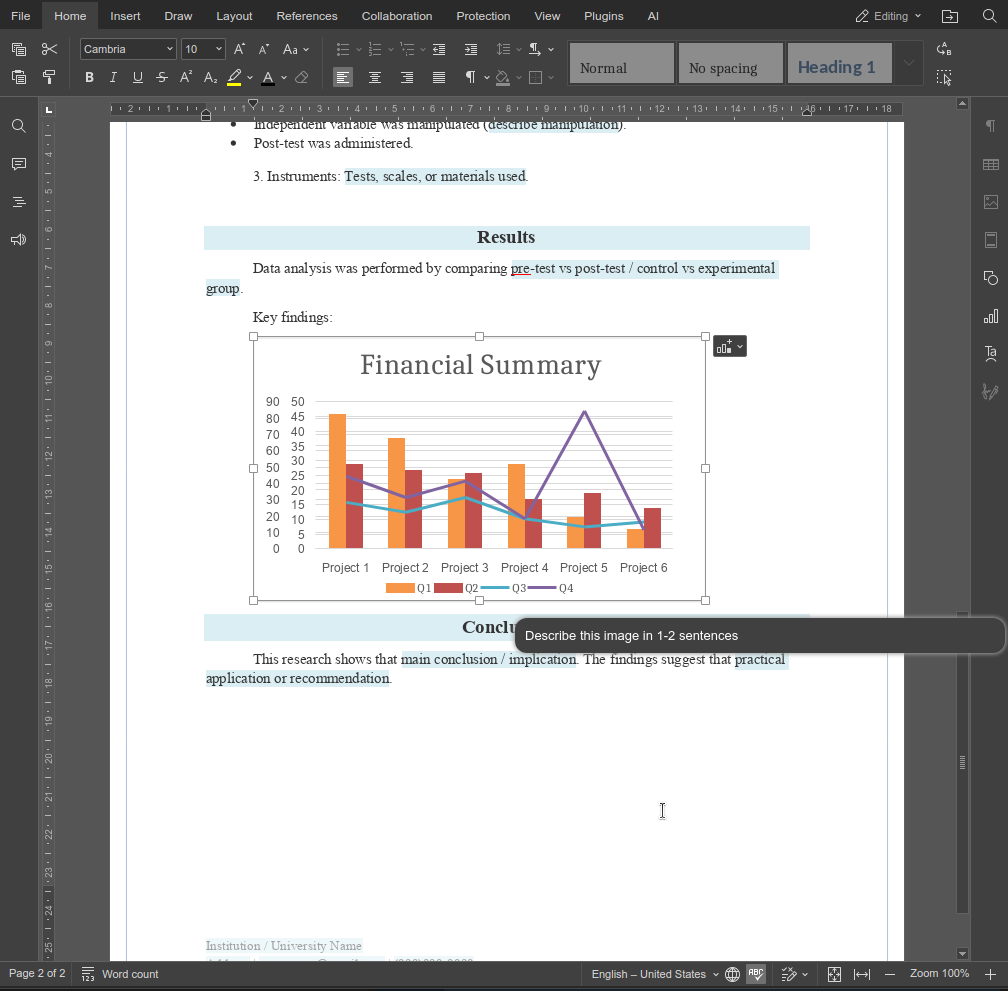
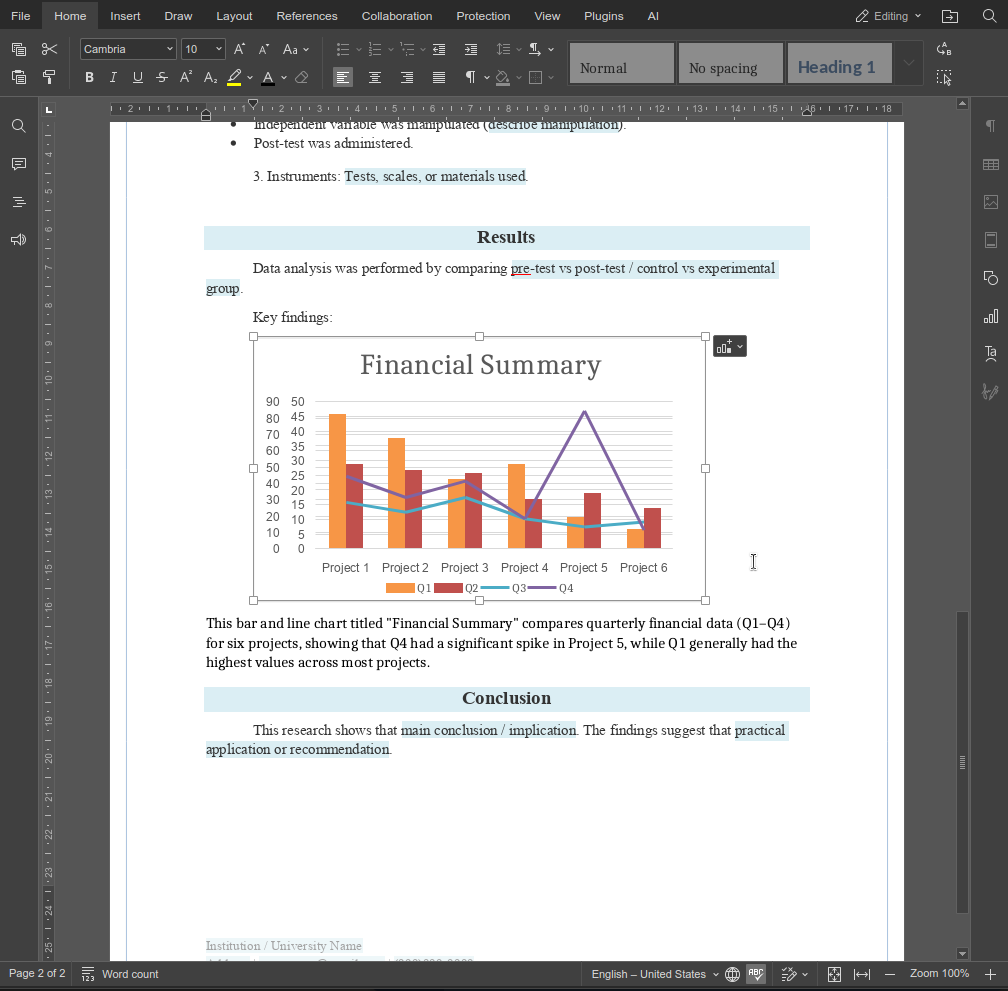
La funzione describeImage mostra come le funzioni personalizzate possano estendere l’agente AI in modi piccoli ma ad alto impatto. Combinando prompt chiari con una logica consapevole dell’editor, puoi creare funzionalità che si integrano direttamente nei flussi di lavoro reali invece di azioni AI generiche.
Prova a creare le tue funzioni uniche per personalizzare le funzionalità del nostro agente AI. Se stai realizzando qualcosa di utile, sentiti libero di condividerlo con noi tramite la pagina dei contatti.
Crea il tuo account ONLYOFFICE gratuito
Visualizza, modifica e collabora su documenti, fogli, diapositive, moduli e file PDF online.


