Von der Idee zur Umsetzung: Entwicklung einer benutzerdefinierten KI-Funktion zur Bildbeschreibung
Mit unserem KI-Agenten können Sie über die Standardfunktionen eines Editors hinausgehen und benutzerdefinierte Funktionen hinzufügen, die genau auf Ihre Bedürfnisse zugeschnitten sind. Dieser Beitrag beschreibt die Erstellung der Funktion describeImage und erklärt, wie sie Bilder in Titel, Bildunterschriften und barrierefreien Alternativtext umwandelt.

Die Idee
Das Ziel ist einfach: Wählen Sie ein Bild aus, geben Sie eine kurze Anweisung ein und erhalten Sie automatisch generierten Text genau an der gewünschten Stelle. Die Funktion unterstützt gängige Anwendungsfälle wie Bildtitel, Bildunterschriften und Alternativtexte und vermeidet Annahmen über die Nutzerabsicht durch explizite Eingabeaufforderungen.
Funktionsdesign
Um die Funktion für die ONLYOFFICE KI-Engine verfügbar zu machen, wurde sie als RegisteredFunction definiert. Diese Definition legt den Funktionsnamen, die erwarteten Parameter und Beispielaufforderungen fest, die die beabsichtigte Verwendung veranschaulichen.
let func = new RegisteredFunction({
name: "describeImage",
description:
"Allows users to select an image and generate a meaningful title, description, caption, or alt text for it using AI.",
parameters: {
type: "object",
properties: {
prompt: {
type: "string",
description:
"instruction for the AI (e.g., 'Add a short title for this chart.')",
},
},
required: ["prompt"],
},
examples: [
{
prompt: "Add a short title for this chart.",
arguments: { prompt: "Add a short title for this chart." },
},
{
prompt: "Write me a 1-2 sentence description of this photo.",
arguments: {
prompt: "Write me a 1-2 sentence description of this photo.",
},
},
{
prompt: "Generate a descriptive caption for this organizational chart.",
arguments: {
prompt:
"Generate a descriptive caption for this organizational chart.",
},
},
{
prompt: "Provide accessibility-friendly alt text for this infographic.",
arguments: {
prompt:
"Provide accessibility-friendly alt text for this infographic.",
},
},
],
});
Diese Definition erfüllt zwei Zwecke:
- Sie informiert die ONLYOFFICE KI-Engine über die Fähigkeiten der Funktion und die erwarteten Eingaben.
- Sie bietet Anwendungsbeispiele, die sowohl die KI als auch Endbenutzer unterstützen.
Implementierung der Logik
Die Methode call enthält die eigentliche Funktionalität, die beim Aufruf der Funktion durch den Benutzer ausgeführt wird:
- Ausgewähltes Bild abrufen – mithilfe von GetImageDataFromSelection wird das Bild aus dem Dokument abgerufen. Platzhalterbilder werden herausgefiltert, um aussagekräftige KI-Ergebnisse zu gewährleisten.
- KI-Aufforderung erstellen – die Benutzeranweisung wird mit dem Kontext des ausgewählten Bildes kombiniert, um eine klare und handlungsrelevante Aufforderung zu generieren.
- Kompatibilität des KI-Modells prüfen – nur Modelle mit Bildverarbeitungsfunktion (wie GPT-4V oder Gemini) können Bilder verarbeiten. Der Benutzer wird benachrichtigt, falls sein aktuelles Modell keine Bilder verarbeiten kann.
- Anfrage an die KI senden – Bild und Aufforderung werden über chatRequest an die KI-Engine gesendet, wobei der generierte Text in Echtzeit erfasst wird.
- KI-generierten Text in das Dokument einfügen – die Funktion erkennt, ob ein Bild ausgewählt ist, und fügt das Ergebnis entsprechend ein.
- Fehlerbehandlung – die Funktion behandelt fehlende Bilder, nicht unterstützte Modelle oder unerwartete KI-Fehler und gibt dem Benutzer entsprechende Fehlermeldungen aus.
1. Abrufen des ausgewählten Bildes
In ONLYOFFICE werden Bilder in einem Dokument als Zeichnungen (drawings) bezeichnet. Zur Verarbeitung eines vom Benutzer ausgewählten Bildes verwenden wir die ONLYOFFICE-Plugin-API:
let imageData = await new Promise((resolve) => {
window.Asc.plugin.executeMethod(
"GetImageDataFromSelection",
[],
function (result) {
resolve(result);
}
);
});
- GetImageDataFromSelection ist eine Methode des ONLYOFFICE-Plugins, die das aktuell ausgewählte Bild als Base64-kodierten String extrahiert.
- Das Ergebnis ist ein Objekt, typischerweise:
{
"src": "data:image/png;base64,iVBORw0K...",
"width": 600,
"height": 400
}
Dieser src-String enthält das gesamte Bild im Base64-Format und kann direkt an KI-Modelle gesendet werden, die Bilddaten verarbeiten.
Wichtige Hinweise:
- Wenn kein Bild ausgewählt ist, ist imageData null.
- Manche Benutzer wählen möglicherweise Platzhaltergrafiken oder leere Rechtecke aus. ONLYOFFICE verwendet beispielsweise ein kleines weißes Rechteck als Platzhalter für leere Bilder. Wir vergleichen dieses mit seiner Base64-Darstellung, um solche Bilder herauszufiltern.
const whiteRectangleBase64 = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mP8/5+hHgAHggJ/PchI7wAAAABJRU5ErkJggg==";
if (imageData.src === whiteRectangleBase64) {
console.log("describeImage: Image is white placeholder");
await insertMessage("Please select a valid image first.");
return;
}
2. Bildaufbereitung für KI
KI-Modelle erwarten Bilder als URLs oder Base64-kodierte Daten, typischerweise in einem Feld wie image_url. In unserer Funktion übergeben wir das Bild zusammen mit einer Texteingabeaufforderung in einem strukturierten Array:
let messages = [
{
role: "user",
content: [
{ type: "text", text: argPrompt },
{
type: "image_url",
image_url: { url: imageData.src, detail: "high" },
},
],
},
];
- type: „text“ enthält die Eingabeaufforderung (z. B. „Füge eine beschreibende Bildunterschrift hinzu“).
- type: „image_url“ enthält das Bild selbst. Die KI-Engine kann das Bild analysieren und relevanten Text generieren.
- detail: „high“ ist ein optionaler Hinweis für die Modelle, das Bild in voller Auflösung zu verarbeiten.
Transformationslogik:
- ONLYOFFICE stellt src als Base64-String bereit.
- KI-Modelle können entweder Base64-Daten oder eine zugängliche URL akzeptieren. Hier verwenden wir Base64 direkt, um das Hochladen auf einen externen Server zu vermeiden.
- Wir kapseln das Bild in ein Objekt, das mit der Chat-Anfrage-API der KI kompatibel ist. Diese Struktur ermöglicht mehrere Inhaltstypen in einer einzigen Nachricht.
3. Anfrage an die KI senden
Sobald Bild und Aufgabenstellung strukturiert sind, verwenden wir die ONLYOFFICE KI-Plugin-Engine:
let requestEngine = AI.Request.create(AI.ActionType.Chat);
await requestEngine.chatRequest(messages, false, async function (data) {
console.log("describeImage: chatRequest callback data chunk", data);
if (data) {
resultText += data;
}
});
- AI.ActionType.Chat ermöglicht das Versenden von Chat-Nachrichten, in denen die Eingabeaufforderung und das Bild gemeinsam analysiert werden.
- Der Callback sammelt in Echtzeit Teile des KI-Antworttextes.
- Vor dem Senden prüfen wir, ob das ausgewählte KI-Modell Bildverarbeitung unterstützt. Nur bestimmte Modelle (GPT-4V, Gemini) können Bilder verarbeiten.
const allowVision = /(vision|gemini|gpt-4o|gpt-4v|gpt-4-vision)/i;
if (!allowVision.test(requestEngine.modelUI.name)) {
console.warn("describeImage: Model does not support vision", requestEngine.modelUI.name);
await insertMessage(
"⚠ This model may not support images. Please choose a vision-capable model (e.g. GPT-4V, Gemini, etc.)."
);
return;
}
4. Einfügen des KI-Textes in das Dokument
Nachdem der KI-Text empfangen wurde, muss er in das ONLYOFFICE-Dokument eingefügt werden. Die Logik berücksichtigt zwei Fälle:
- Bild ausgewählt: Nach dem Bild einen Absatz einfügen.
- Kein Bild ausgewählt: Nach der aktuellen Cursorposition einen Absatz einfügen.
async function insertMessage(message) {
console.log("describeImage: insertMessage called", message);
Asc.scope._message = String(message || "");
await Asc.Editor.callCommand(function () {
const msg = Asc.scope._message || "";
const doc = Api.GetDocument();
const selected =
(doc.GetSelectedDrawings && doc.GetSelectedDrawings()) || [];
if (selected.length > 0) {
for (let i = 0; i < selected.length; i++) {
const drawing = selected[i];
const para = Api.CreateParagraph();
para.AddText(msg);
drawing.InsertParagraph(para, "after", true);
}
} else {
const para = Api.CreateParagraph();
para.AddText(msg);
let range = doc.GetCurrentParagraph();
range.InsertParagraph(para, "after", true);
}
Asc.scope._message = "";
}, true);
- Api.GetSelectedDrawings() ruft die aktuell ausgewählten Bilder (Zeichnungen) ab.
- Api.CreateParagraph() erstellt ein neues Absatzobjekt.
- InsertParagraph(para, „after“, true) fügt den generierten Text direkt nach dem ausgewählten Bild oder Absatz ein.
- Dies gewährleistet eine nahtlose Integration: Die KI-Ausgabe erscheint stets im richtigen Kontext.
5. Umgang mit Sonderfällen und Fehlern
Einige Herausforderungen erforderten besondere Aufmerksamkeit:
- Kein Bild ausgewählt – Benutzer zur Auswahl eines Bildes auffordern.
- Nicht unterstütztes KI-Modell – Benutzer vor dem Senden einer Anfrage warnen.
- Leere KI-Antwort – Benutzer darüber informieren, dass die KI keine Beschreibung generieren konnte.
- Unerwartete Fehler – Verschachtelte try/catch-Blöcke verwenden, um laufende Bearbeitungsaktionen sicher zu beenden.
} catch (e) {
try {
await Asc.Editor.callMethod("EndAction", ["GroupActions"]);
await Asc.Editor.callMethod("EndAction", [
"Block",
"AI (describeImage)",
]);
} catch (ee) {
}
Dadurch wird sichergestellt, dass das Dokument auch dann stabil bleibt, wenn die KI oder das Plugin während des Vorgangs ausfällt.
Endergebnis
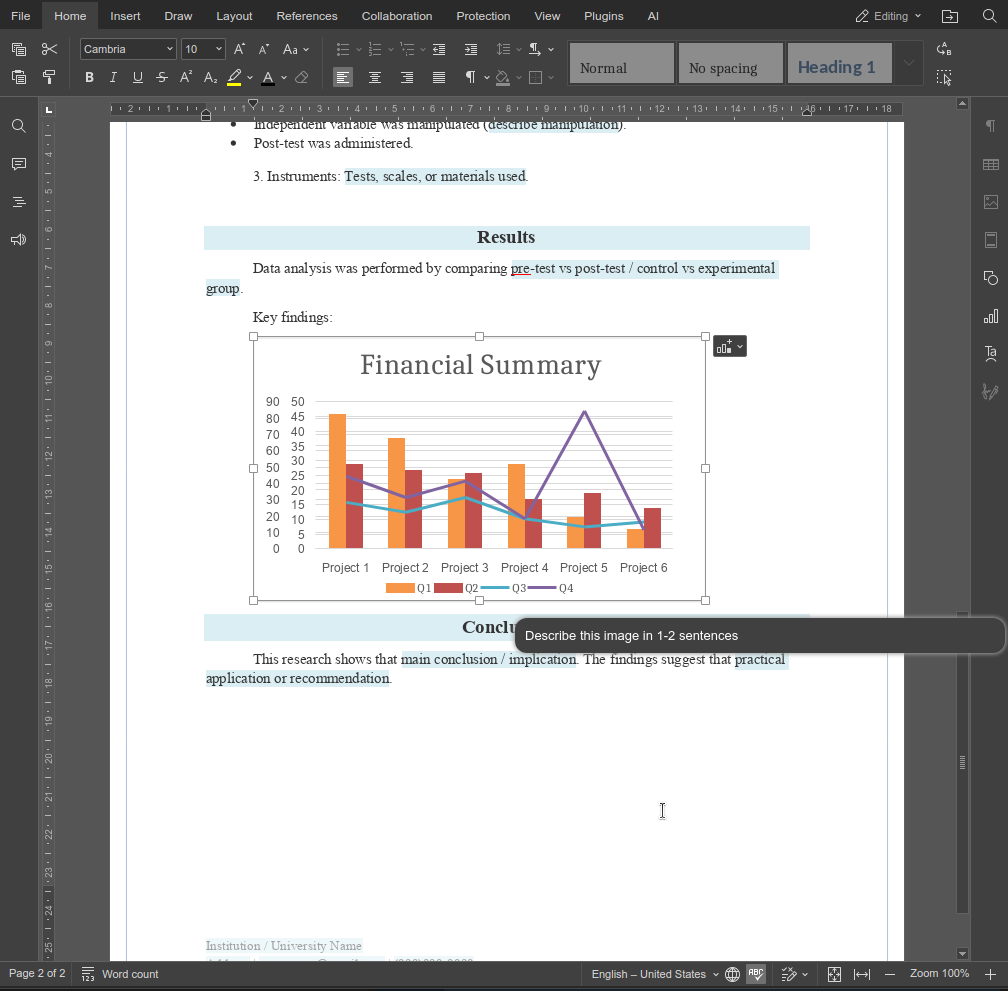
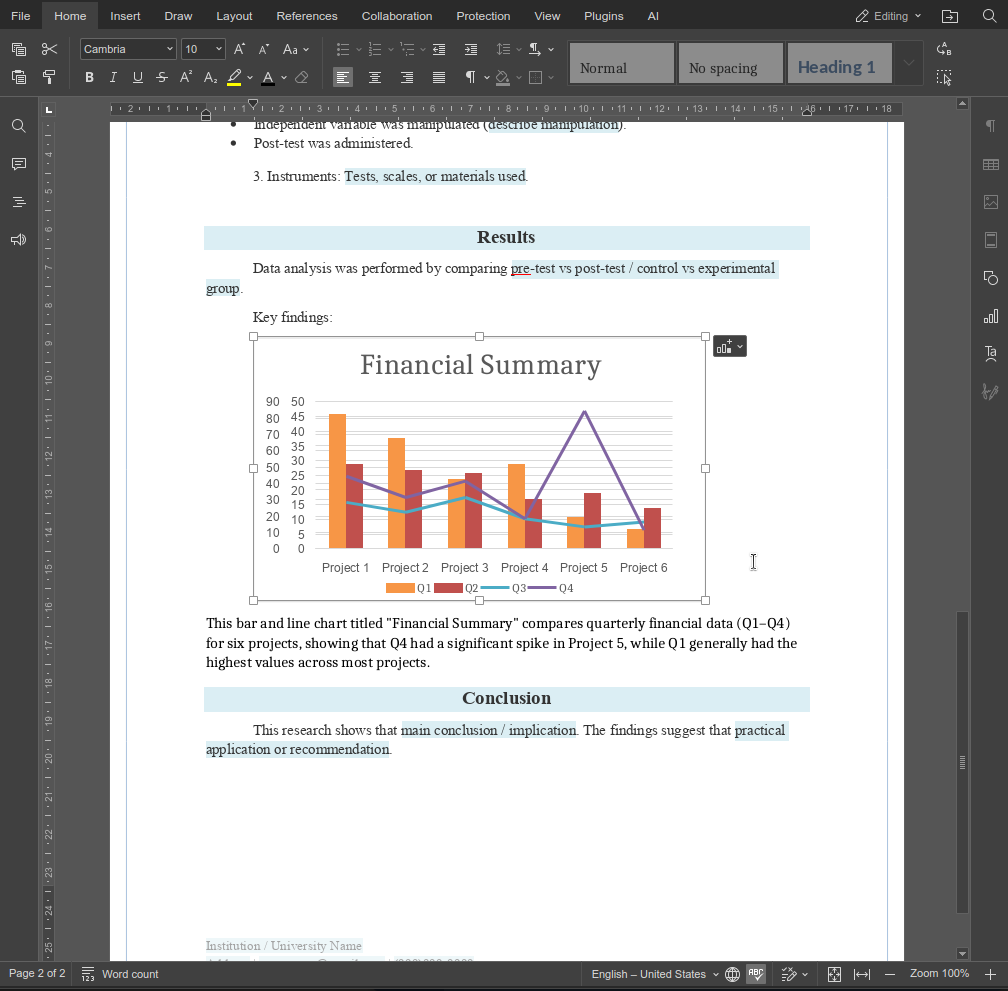
Die Funktion describeImage zeigt, wie benutzerdefinierte Funktionen den KI-Agenten auf kleine, aber wirkungsvolle Weise erweitern können. Durch die Kombination von klaren Anweisungen mit editorspezifischer Logik lassen sich Funktionen entwickeln, die sich direkt in reale Arbeitsabläufe integrieren lassen, anstatt generische KI-Aktionen auszuführen.
Probieren Sie es selbst aus und erstellen Sie eigene Funktionen, um die Funktionalität unseres KI-Agenten anzupassen. Wenn Sie etwas Nützliches entwickeln, teilen Sie es uns gerne über die Kontaktseite mit.
Erstellen Sie Ihr kostenloses ONLYOFFICE-Konto
Öffnen und bearbeiten Sie gemeinsam Dokumente, Tabellen, Folien, Formulare und PDF-Dateien online.


